
#spark#parquet#column storage#performance
데이터
Apache Spark에서 컬럼 기반 저장 포맷 Parquet(파케이) 제대로 활용하기
Kevin Kim
2018년 5월 24일7분 소요
VCNC에서는 데이터 분석을 위해 다양한 로그를 수집, 처리하는데 대부분은 JSON 형식의 로그 파일을 그대로 압축하여 저장해두고 Apache Spark으로 처리하고 있었습니다. 이렇게 Raw data를 바로 처리하는 방식은 ETL을 통해 데이터를 전처리하여 두는 방식과 비교하면 데이터 관리비용에서 큰 장점이 있지만, 매번 불필요하게 많은 양의 데이터를 읽어들여 처리해야 하는 아쉬움도 있었습니다.
이러한 아쉬움을 해결하기 위해 여러 논의 중 데이터 저장 포맷을 Parquet로 바꿔보면 여러가지 장점이 있겠다는 의견이 나왔고, 마침 Spark에서 Parquet를 잘 지원하기 때문에 저장 포맷 변경 작업을 하게 되었습니다. 결론부터 말하자면 74%의 저장 용량 이득, 10~30배의 처리 성능 이득을 얻었고 성공적인 작업이라고 평가하지만 그 과정은 간단하지만은 않았습니다. 그 과정과 이를 통해 깨달은 점을 이 글을 통해 공유해 봅니다.
Parquet(파케이)에 대해
Parquet(파케이)는 나무조각을 붙여넣은 마룻바닥이라는 뜻을 가지고 있습니다. 데이터를 나무조각처럼 차곡차곡 정리해서 저장한다는 의도로 지은 이름이 아닐까 생각합니다.
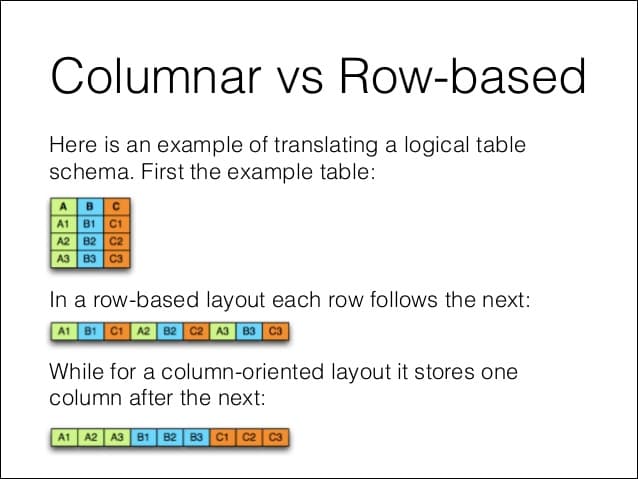
빅데이터 처리는 보통 많은 시간과 비용이 들어가므로 압축률을 높이거나, 데이터를 효율적으로 정리해서 처리하는 데이터의 크기를 1/2 혹은 1/3로 줄일 수 있다면 이는 매우 큰 이득입니다. 데이터를 이렇게 극적으로 줄일 수 있는 아이디어 중 하나가 컬럼 기반 포맷입니다. 컬럼 기반 포맷은 같은 종류의 데이터가 모여있으므로 압축률이 더 높고, 일부 컬럼만 읽어 들일 수 있어 처리량을 줄일 수 있습니다.
Parquet(파케이)는 하둡 생태계의 어느 프로젝트에서나 사용할 수 있는 효율적인 컬럼 기반 스토리지를 표방하고 있습니다. Twitter의 “Julien Le Dem” 와 Impala 프로젝트 Lead였던 Cloudera의 “Nong Li”가 힘을 합쳐 개발한 프로젝트로 현재는 많은 프로젝트에서 Parquet를 지원하고 컬럼 기반 포맷의 업계 표준에 가깝습니다.
Parquet를 적용해보니 Apache Spark에서는, 그리고 수많은 하둡 생태계의 프로젝트들에서는 Parquet를 잘 지원합니다.
val data = spark.read.parquet("PATH")
data.write.parquet("PATH")Spark에서는 이런 식으로 손쉽게 parquet 파일을 읽고, 쓸 수가 있습니다. 데이터를 분석하기 전에 원본이라고 할 수 있는 gzipped text json을 읽어서 Parquet 로 저장해두고 (gzipped json은 S3에서 glacier로 이동시켜버리고), 이후에는 Parquet에서 데이터를 읽어서 처리하는 것 만으로도 저장용량과 I/O 면에서 어느 정도의 이득을 얻을 수 있었습니다. 하지만 테스트 결과 저장용량에서의 이득이 gz 23 GB 에서 Parquet 18GB 로 1/3 정도의 저장용량을 기대했던 만큼의 개선이 이루어지지는 않았습니다.
Parquet Deep Dive
상황을 파악하기 위해 조금 더 조사를 해보기로 하였습니다. Parquet의 포맷 스팩은 Parquet 프로젝트 에서 관리되고 있고, 이의 구체적인 구현체로 parquet-mr 이나 parquet-cpp 프로젝트 등에서 스펙을 구현하고 있습니다. 그리고 특별한 경우에는 Spark에서는 Spark 내부에 구현된 VectorizedParquetRecordReader 에서 Parquet 파일을 처리하기도 합니다.
파일 포맷이 바뀌거나 기능이 추가되는 경우에는 쿼리엔진에서도 이를 잘 적용해주어야 합니다. 하지만 안타깝게도 Spark은 parquet-mr 1.10 버전이 나온 시점에도 1.8 버전의 오래된 버전의 parquet-mr 코드를 사용하고 있습니다. (아마 다음 릴리즈(2.4.0)에는 1.10 버전이 적용될 것으로 보이지만)
Parquet 의 메인 개발자 중에는 Impala 프로젝트의 lead도 있기 때문에, Impala에는 비교적 빠르게 변경사항이 반영되는 것에 비하면 대조적입니다. 모든 프로젝트들이 실시간적으로 유기적으로 업데이트되는 것은 힘든 일이기 때문에 어느 정도는 받아들여야겠지만, 우리가 원하는 Parquet의 장점을 취하기 위해서는 여러 가지 옵션을 조정하거나 직접 수정을 해야 합니다.
VCNC 데이터팀에서는 저장 용량과 I/O 성능을 최적화하기 위하여 Parquet의
- Dictionary encoding (String들을 압축할 때 dictionary를 만들어서 압축하는 방식, 길고 반복되는 String이 많다면 좋은 압축률을 기대할 수 있습니다)
- Column pruning (필요한 컬럼만을 읽어 들이는 기법)
- Predicate pushdown, row group skipping (predicate, 즉 필터를 데이터를 읽어 들인 후 적용하는 것이 아니라 저장소 레벨에서 적용하는 기법)
과 같은 기능들을 사용하기를 원했고, 이를 위해 여러 조사를 진행하였습니다.
저장용량 줄이기
102GB의 JSON 포맷 로그를 text그대로 gzip으로 압축하면 23GB가 됩니다. dictionary encoding이 잘 적용되도록 적절한 옵션 설정을 통해 Parquet로 저장하면 6GB로, 기존 압축방식보다 저장 용량을 74%나 줄일 수 있었습니다.
val ndjsonDF = spark.read.schema(_schema).json("s3a://ndjson-bucket/2018/04/05") ndjsonDF. sort("userId", "objectType", "action"). coalesce(20). write. options(Map( ("compression", "gzip"), ("parquet.enable.dictionary", "true"), ("parquet.block.size", s"${32 1024 1024}"), ("parquet.page.size", s"${2 1024 1024}"), ("parquet.dictionary.page.size", s"${8 1024 1024}"), )). parquet("s3a://parquet-bucket/2018/04/05")
비트윈의 로그 데이터는 ID가 노출되지 않도록 익명화하면서 8ptza2HqTs6ZSpvmcR7Jww 와 같이 길어지기에 이러한 항목들이 dictionary encoding을 통해 효과적으로 압축되리라 기대할 수 있었고, Parquet에서는 dictionary encoding이 기본이기에 압축률 개선에 상당히 기대하고 있었습니다.
하지만 parquet-mr 의 구현에서는 dictionary의 크기가 어느 정도 커지면 그 순간부터 dictionary encoding을 쓰지 않고 plain encoding으로 fallback하게 되어 있었습니다. 비트윈에서 나온 로그들은 수많은 동시접속 사용자들의 ID 갯수가 많기 때문에 dictionary의 크기가 상당히 커지는 상태였고, 결국 dictionary encoding을 사용하지 못해 압축 효율이 좋지 못한 상태였습니다.
이를 해결하기 위해, parquet.block.size를 default 값인 128MB에서 32MB로 줄이고 parquet.dictionary.page.size를 default 값 1MB에서 8MB 로 늘려서 ID가 dictionary encoding으로만 잘 저장될 수 있도록 만들었습니다.
처리속도 올리기
저장용량이 줄어든 것으로도 네트워크 I/O가 줄어들기 때문에 처리 속도가 상당히 올라갑니다. 하지만 컬럼 기반 저장소의 장점을 온전하게 활용하기 위해서 column pruning, predicate pushdown들이 제대로 작동하는지 점검하고 싶었습니다.
소스코드를 확인하고 몇 가지 테스트를 해 본 결과, Spark에서는 Parquet의 top level field에서의 column pruning은 지원하지만 nested field들에 대해서는 column pruning을 지원하지 않았습니다. 비트윈 로그에서는 nested field들을 많이 사용하고 있었기에 약간 아쉬웠으나 top level field에서의 column pruning 만으로도 어느 정도 만족스러웠고 로그의 구조도 그대로 사용할 예정입니다.
Predicate pushdown도 실행시간에 크게 영향을 줄 거라 예상했습니다. 그런데 Spark 2.2.1기준으로 column pruning의 경우와 비슷하게, top level field에 대해서만 predicate pushdown이 작동하는 것을 확인할 수 있었습니다. 이는 성능에 큰 영향을 미치기에, predicate 로 자주 사용하는 column들을 top level 로 끌어올려 저장하는 작업을 하게 되었습니다. 여기에 추가로 parquet.string.min-max-statistics 옵션을 손보고 나서야 드디어 10~30배 정도의 성능 향상을 볼 수 있었습니다.
매일 15분 정도 걸리던 "의심스러운 로그인 사용자" 탐지 쿼리가 30여초만에 끝나고, cs처리를 위해 한 사람의 로그만 볼 때 5분 정도 걸리던 쿼리가 30여초만에 처리되게 되었습니다.
못다 한 이야기
parquet.string.min-max-statistics 옵션과 row group skipping에 관해.
Parquet 같은 포맷 입장에서 string 혹은 binary 필드의 순서를 판단하기는 어렵습니다. 예를 들어 글자 á 와 e 가 있을 때 어느 쪽이 더 작다고 할까요? 사전 편찬자라면 á가 더 작다고 볼 것이고, byte 표현을 보면 á는 162이고 e는 101이라 e가 더 작습니다. Parquet 같은 저장 포맷 입장에서는 binary 필드가 있다는 사실만 알고 있고, 그 필드에 무엇이 저장될지, 예를 들어 á와 e가 저장되는지, 이미지의 blob가 저장되는지는 알 수 없습니다. 그러니 순서를 어떻게 정해야 할지는 더더구나 알 수 없습니다.
그래서 Parquet 내부적으로 컬럼의 min-max 값을 저장해 둘 때, 1.x 버전에서는 임의로 byte sequence를 UNSINGED 숫자로 해석해 그 컬럼의 min-max 값을 정해 저장했습니다. 이후에 이를 개선하기 위해 Ryan Blue가 PARQUET-686에서 parquet-format에 SORT_ORDER를 저장할 수 있도록 했습니다.
여기에서 문제는 이전 버전과의 호환성입니다. SORT_ORDER가 없던 시절의 Parquet 파일을 읽으려 할 때, min-max 값을 사용해 row group skipping이 일어나면 query 엔진에서 올바르지 않은 결과가 나올 수 있으니, binary 필드의 min-max 값을 parquet-mr 에서 아예 반환하지 않게 되어있습니다.
하지만 이는 우리가 원하는 동작이 아닙니다. 여기에 parquet.string.min-max-statistics option을 true로 설정하면, 이전처럼 binary필드의 min-max값을 리턴하게 되고 rowgroup skipping이 작동하여 쿼리 성능을 크게 올릴 수 있습니다.
마치며
Spark과 Parquet 모두 많은 사람이 사랑하는 훌륭한 오픈소스 프로젝트입니다. 또한 별다른 설정이나 튜닝 없이 기본 설정만으로도 잘 돌아가는 편이기 때문에 더더욱 많은 사람이 애용하는 프로젝트이기도 합니다.
하지만 오픈소스는 완전하지 않습니다. 좋은 엔지니어링 팀이라면 단지 남들이 많이 쓰는 오픈소스 프로젝트들을 조합해서 사용하는 것에서 그치지 않고 핵심 원리와 내부 구조를 연구해가며 올바르게 활용해야 한다고 생각합니다. 기술의 올바른 활용을 위해 비트윈 데이터팀은 오늘도 노력하고 있습니다.


