![주스를 만드는 과정에 빗대어 MapReduce를 설명한 그림.
함수형 프로그래밍의 기본 개념인 Map, Reduce라는 프레임을 활용하여 여러 가지 문제를 병렬적으로 처리할 수 있다.
[MapReduce slideshare] 참조](/_next/image?url=%2Fposts%2Fimages%2F2015-05-18-data-analysis-with-spark%2Fmap-reduce-drink.png&w=3840&q=75)


![Spark과 MapReduce의 성능 비교. I/O intensive 한 작업은 성능이 극적으로 향상되며, CPU intensive 한 작업의 경우에도 효율이 더 높다. (자료: [RDD 논문])](/_next/image?url=%2Fposts%2Fimages%2F2015-05-18-data-analysis-with-spark%2Fspark-performance.png&w=3840&q=75)
#Apache Spark#스파크#Apache Zeppelin#제플린#데이터 분석#빅데이터#AWS S3
데이터
VCNC가 Hadoop대신 Spark를 선택한 이유
Kevin Kim
2015년 5월 18일7분 소요
요즘은 데이터 분석이 스타트업, 대기업 가릴 것 없이 유행입니다. VCNC도 비트윈 출시 때부터 지금까지 데이터 분석을 해오고 있고, 데이터 기반의 의사결정을 내리고 있습니다.
데이터 분석을 하는데 처음부터 복잡한 기술이 필요한 것은 아닙니다. Flurry, Google Analytics 등의 훌륭한 무료 툴들이 있습니다. 하지만 이러한 범용 툴에서 제공하는 것 이상의 특수하고 자세한 분석을 하고 싶을 때 직접 많은 데이터를 다루는 빅데이터 분석을 하게 됩니다. VCNC에서도 비트윈의 복잡한 회원 가입 프로세스나, 채팅, 모멘츠 등 다양한 기능에 대해 심층적인 분석을 위해 직접 데이터를 분석하고 있습니다.
빅데이터 분석 기술
큰 데이터를 다룰 때 가장 많이 쓰는 기술은 Hadoop MapReduce와 연관 기술인 Hive입니다. 구글의 논문으로부터 영감을 받아 이를 구현한 오픈소스 프로젝트인 Hadoop은 클러스터 컴퓨팅 프레임웍으로 비싼 슈퍼컴퓨터를 사지 않아도, 컴퓨터를 여러 대 연결하면 대수에 따라서 데이터 처리 성능이 스케일되는 기술입니다. 세상에 나온지 10년이 넘었지만 아직도 잘 쓰이고 있으며 데이터가 많아지고 컴퓨터가 저렴해지면서 점점 더 많이 쓰이고 있습니다. VCNC도 작년까지는 데이터 분석을 하는데 MapReduce를 많이 사용했습니다.
MapReduce는 슈퍼컴퓨터 없이도 저렴한 서버를 여러 대 연결하여 빅데이터 분석을 가능하게 해 준 혁신적인 기술이지만 10년이 지나니 여러 가지 단점들이 보이게 되었습니다. 우선 과도하게 복잡한 코드를 짜야합니다. 아래는 간단한 Word Count 예제를 MapReduce로 구현한 것인데 매우 어렵고 복잡합니다.
이의 대안으로 SQL을 MapReduce로 변환해주는 Hive 프로젝트가 있어 많은 사람이 잘 사용하고 있지만, 쿼리를 최적화하기가 어렵고 속도가 더 느려지는 경우가 많다는 어려움이 있습니다.
MapReduce의 대안으로 최근 아주 뜨거운 기술이 있는데 바로 Apache Spark입니다. Spark는 Hadoop MapReduce와 비슷한 목적을 해결하기 위한 클러스터 컴퓨팅 프레임웍으로, 메모리를 활용한 아주 빠른 데이터 처리가 특징입니다. 또한, 함수형 프로그래밍이 가능한 언어인 Scala를 사용하여 코드가 매우 간단하며, interactive shell을 사용할 수 있습니다.
Apache Spark는 미국이나 중국에서는 현재 Hadoop을 대체할만한 기술로 급부상하고 있으며, 국내에도 최신 기술에 발 빠른 사람들은 이미 사용하고 있거나, 관심을 갖고 있습니다. 성능이 좋고 사용하기 쉬울 뿐 아니라, 범용으로 사용할 수 있는 프레임웍이기에 앞으로 더 여러 분야에서 많이 사용하게 될 것입니다. 아직 Spark를 접해보지 못하신 분들은 한번 시간을 내어 살펴보시길 추천합니다.
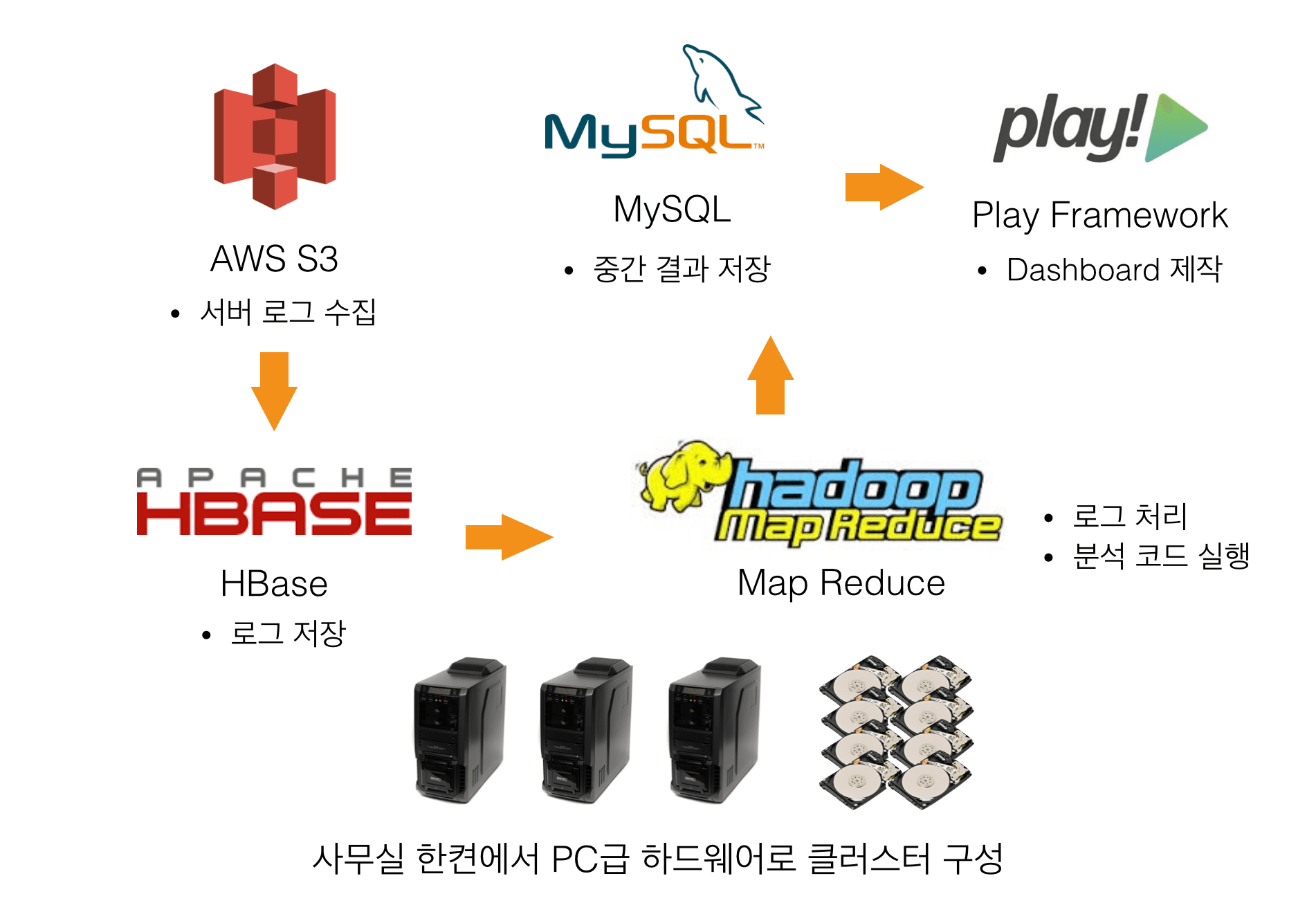
기존의 데이터 분석 시스템 아키텍처
기존의 시스템은 비용을 줄이기 위해 머신들을 사무실 구석에 놓고 직접 관리했으며, AWS S3 Tokyo Region에 있는 로그를 다운받아 따로 저장한 뒤, MapReduce로 계산을 하고 dashboard를 위한 사이트를 따로 제작하여 운영하고 있었습니다.
이러한 시스템은 빅데이터 분석을 할 수 있다는 것 외에는 불편한 점이 많았습니다. 자주 고장 나는 하드웨어를 수리하느라 바빴고, 충분히 많은 머신을 확보할 여유가 없었기 때문에 분석 시간도 아주 오래 걸렸습니다. 그리고 분석부터 시각화까지 과정이 복잡하였기 때문에 간단한 것이라도 구현하려면 시간과 노력이 많이 들었습니다.
Spark과 Zeppelin을 만나다
이때 저희의 관심을 끈 것이 바로 Apache Spark입니다. MapReduce에 비해 성능과 인터페이스가 월등히 좋은 데다가 0.x 버전과는 달리 1.0 버전에서 많은 문제가 해결되면서 안정적으로 운영할 수 있어 비트윈 데이터 분석팀에서는 Spark 도입을 결정했습니다.
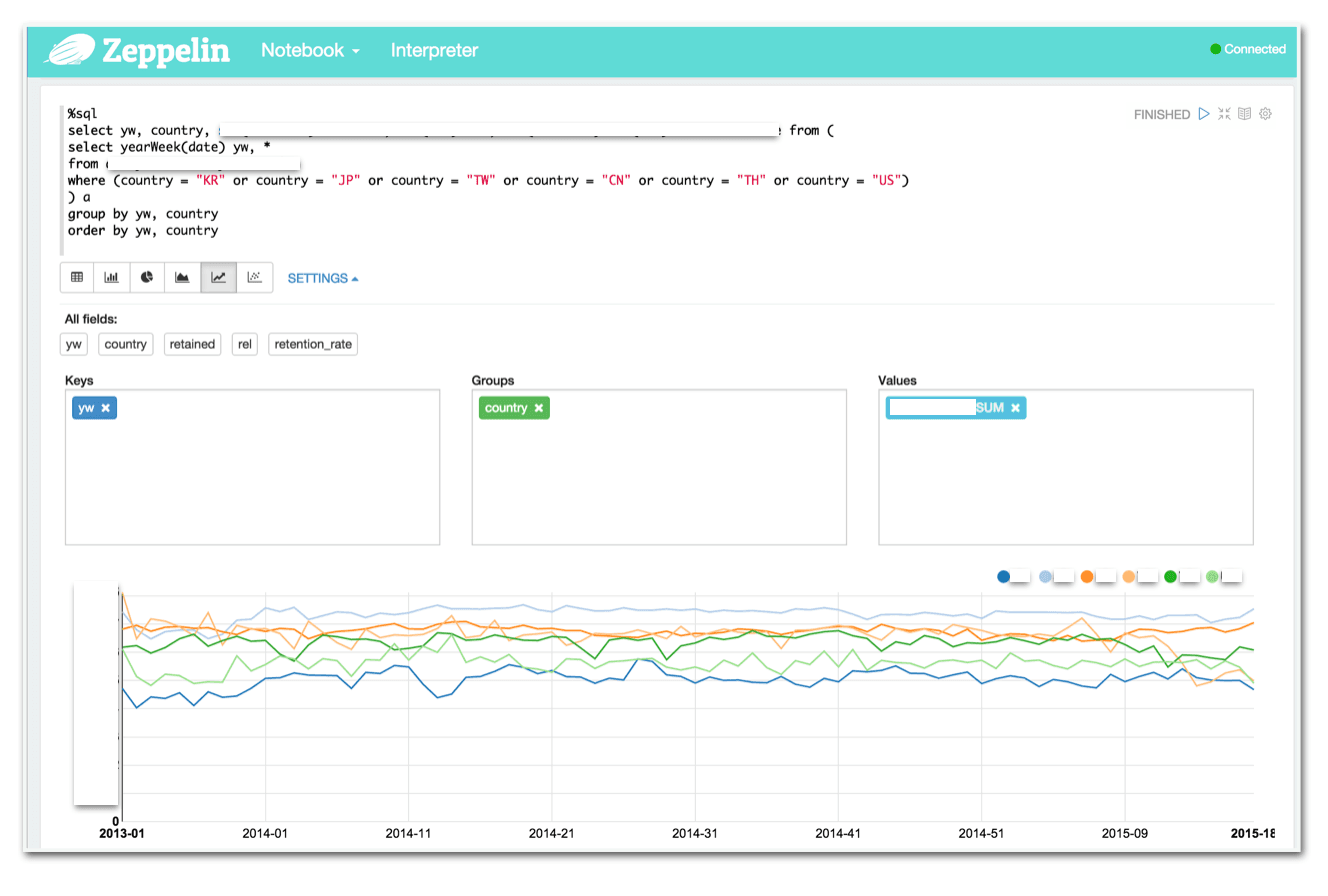
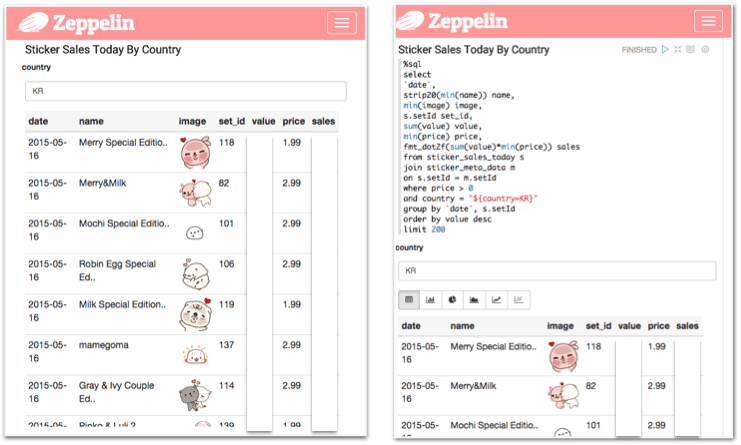
Apache Zeppelin은 국내에서 주도하고 있는 오픈소스 프로젝트로써, Spark를 훨씬 더 편하고 강력하게 사용할 수 있게 해주는 도구입니다. 주요한 역할은 노트북 툴, 즉 shell에서 사용할 코드를 기록하고 재실행할 수 있도록 관리해주는 역할과 코드나 쿼리의 실행 결과를 차트나 표 등으로 시각화해서 보여주는 역할입니다. VCNC에서는 Zeppelin의 초기 버전부터 관심을 가지고 살펴보다가, Apache Spark를 엔진으로 사용하도록 바뀐 이후에 활용성이 대폭 좋아졌다고 판단하여 데이터 분석에 Zeppelin을 도입하여 사용하고 있고, 개발에도 참여하고 있습니다.
또한, 위에서 언급한 하드웨어 관리에 드는 노력을 줄이기 위해서 전적으로 클라우드를 사용하기로 함에 따라서^1 아래와 같은 새로운 구조를 가지게 되었습니다.
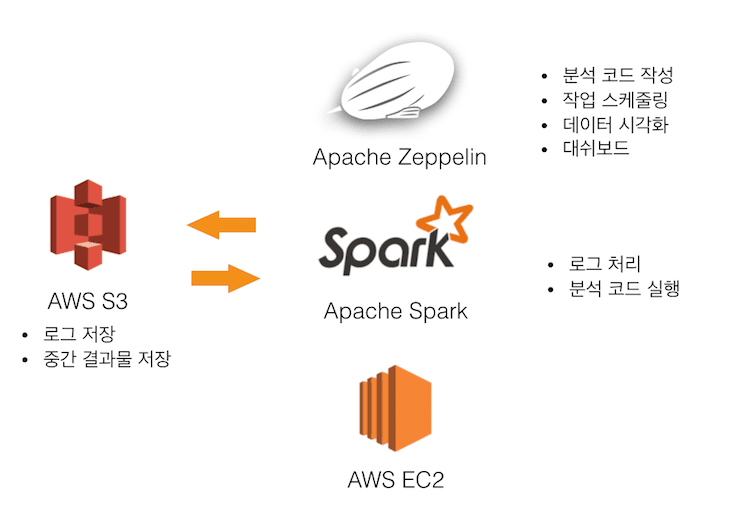
새로운 데이터 분석 시스템 아키텍처
새로운 데이터 분석 시스템은 아키텍처라고 하기에 다소 부끄러울 정도로 간단합니다. 애초에 전체 시스템 구성을 간단하게 만드는 것에 중점을 두었기 때문입니다. 대략적인 구성과 활용법은 아래와 같습니다.
- 모든 서버는 AWS 클라우드를 이용
- 수 대의 Zeppelin 서버, 수 대의 Spark 서버운영
- Spark 서버는 메모리가 중요하므로 EC2 R3 instance 사용
- 로그는 별도로 저장하지 않고 서비스 서버에서 S3로 업로드하는 로그를 곧바로 가져와서 분석함
- 중간 결과 저장도 별도의 데이터베이스를 두지 않고 S3에 파일로 저장
- Zeppelin의 scheduler 기능을 이용하여 daily batch 작업 수행
- 별도의 dashboard용 Zeppelin을 통해 중간 결과를 시각화하며 팀에 결과 공유
이렇게 간단한 구조이긴 하지만 Apache Spark와 Apache Zeppelin을 활용한 이 시스템의 능력은 기존 시스템보다 더 강력하고, 더 다양한 일을 더 빠르게 해낼 수 있습니다.
| 기존 | 현재 | |
|---|---|---|
| 일일 배치 분석 | 코드 작성 및 관리가 어려움 | Zeppelin의 Schedule 기능을 통해 수행 </br> Interactive shell로 쉽게 데이터를 탐험 </br> 오류가 생긴 경우에 shell을 통해 손쉽게 원인 발견 및 수정 가능 |
| Ad-hoc(즉석) 분석 | 복잡하고 많은 코드를 짜야 함 </br> 분석 작업에 수 일 소요 | Interactive shell 환경에서 즉시 분석 수행 가능 |
| Dashboard | 별도의 사이트를 제작하여 운영 </br> 관리가 어렵고 오류 대응 힘듦 | Zeppelin report mode 사용해서 제작 </br> 코드가 바로 시각화되므로 제작 및 관리 수월 |
| 성능 | 일일 배치 분석에 약 8시간 소요 | 메모리를 활용하여 동일 작업에 약 1시간 소요 |
이렇게 시스템을 재구성하는 작업이 간단치는 않았습니다. 이전 시스템을 계속 부분적으로 운영하면서 점진적으로 재구성 작업을 하였는데 대부분 시스템을 옮기는데 약 1개월 정도가 걸렸습니다. 그리고 기존 시스템을 완전히 대체하는 작업은 약 6개월 후에 종료되었는데, 이는 분석 성능이 크게 중요하지 않은 부분들에 대해서는 시간을 두고 여유 있게 작업했기 때문이었습니다.
결론
비트윈 데이터 분석팀은 수개월에 걸쳐 데이터 분석 시스템을 전부 재구성하였습니다. 중점을 둔 부분은
- 빠르고 효율적이며 범용성이 있는 Apache Spark, Apache Zeppelin을 활용하는 것
- 최대한 시스템을 간단하게 구성하여 관리 포인트를 줄이는 것
두 가지였고, 그 결과는 매우 성공적이었습니다.
우선 데이터 분석가 입장에서도 관리해야 할 포인트가 적어져 부담이 덜하고, 이에 따라 Ad-hoc분석을 수행할 수 있는 시간도 늘어나 여러 가지 데이터 분석 결과를 필요로 하는 다른 팀들의 만족도가 높아졌습니다. 새로운 기술을 사용해 본 경험을 글로 써서 공유하고, 오픈소스 커뮤니티에 기여할 수 있는 시간과 기회도 생겼기 때문에 개발자로서 보람을 느끼고 있습니다.
물론 새롭게 구성한 시스템이 장점만 있는 것은 아닙니다. 새로운 기술들로 시스템을 구성하다 보니 세세한 기능들이 아쉬울 때도 있고, 안정성도 더 좋아져야 한다고 느낍니다. 대부분 오픈소스 프로젝트이므로, 이러한 부분은 적극적으로 기여하여 개선하여 나갈 계획입니다.
비트윈 팀에서는 더 좋은 개발환경, 분석환경을 위해 노력하고 있으며 이는 더 좋은 서비스를 만들기 위한 중요한 기반이 된다고 생각합니다. 저희는 항상 좋은 개발자를 모시고 있다는 광고와 함께 글을 마칩니다.

이 글이 도움이 되었나요?

